On Friday I accepted a challenge to clone Reddit's /r/place in a weekend. And I did it, and its live, and its amazing:
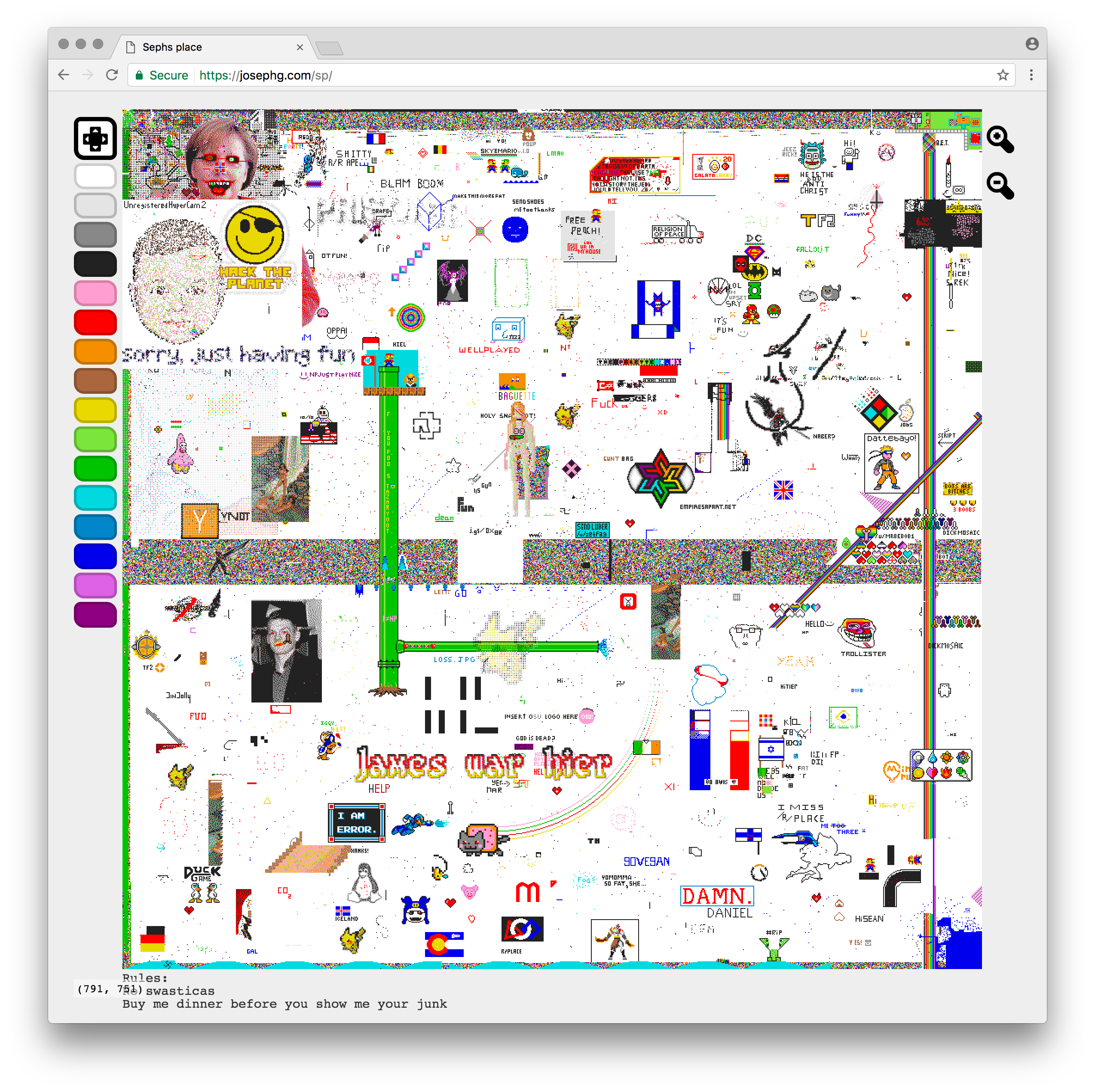
Being able to build this in a weekend isn't genius. Its possible because programming is made up of 2 activities:
- Making decisions (95%)
- Typing (5%)
Reddit wrote up a wonderful blog post about how they made the original, so lots of the decisions were already made for me. How much load I need to handle, how big to make it, the palette and some of the UI I'm using directly. I didn't copy reddit's architecture though, simply because I don't agree with some of their technical decisions. But the places in which I disagree are all based on decades of my own programming experience, so I still don't have a lot of decisions left to make.
To be clear, if I was building this for reddit a weekend wouldn't be enough time. The code is a mess. There's no monitoring and logging. No CI, no tests. There's no access control and no mobile support. I also haven't load tested it as thoroughly as reddit would need to. A weekend is not enough time to make it production ready for a site like reddit.
But thats ok - it sure works! And some quick benchmarking shows it should scale past reddit's 100k users mark.

How it works
I had a think about how I wanted data to flow through the app before I even accepted the challenge. It was important to know so I could figure out if I could actually build it in time.
My favorite architecture for this sort of thing is to use event sourcing and make data flow one way though the site. If you've ever used Redux with react you'll appreciate how simple this makes everything - every part of the system just has 2 responsibilities:
- Where do I get data from?
- Where do I send the data?
So, for sephsplace edits start in the browser, hit a server, go to kafka, get read from kafka by a server then get sent to users.
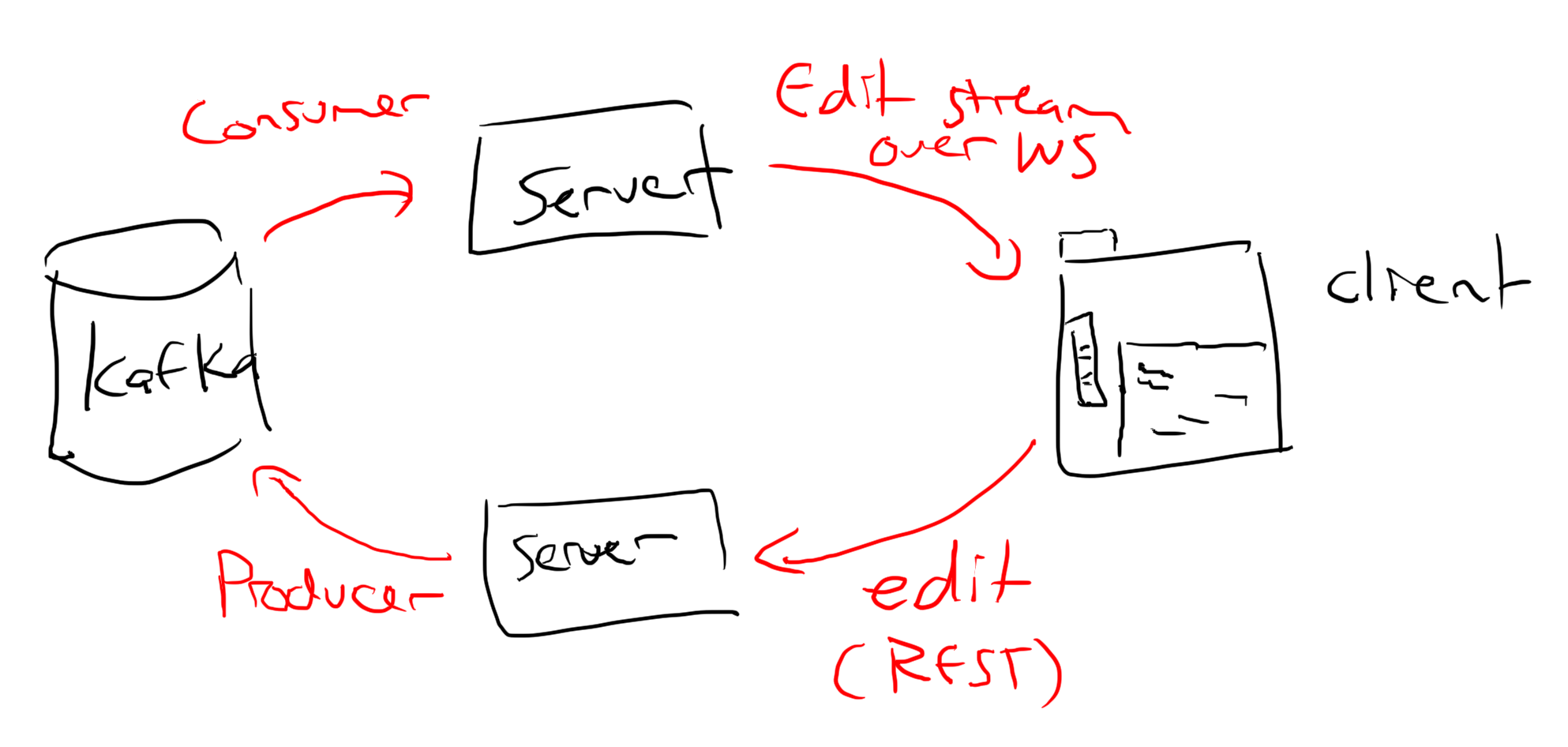
Which is simple enough. The edits themselves are globally ordered by kafka, so if two edits to the same location happen at the same time, everyone will see the same final result based on the order they come back out of kafka. You could make a fancier event log which load balanced edits across multiple kafka partitions, but reddit's spec says it only needs to handle 333 edits per second. A single kafka partition should be able to manage 10-100x that much load.
To ensure consistency I attach a version number to each edit coming out of the kafka event stream. So, the first edit was edit 0, then edit 1 and so on. At the time of writing we're up to edit 333721. (Check window._version on the site if you're curious.)
Subscribe from version
The genius of this system is that if you have an image that is out of date, so long as you know the version we can catch you up by just sending some edits.
For example, if you get disconnected while at version 1000, when you reconnect you just have to download all the operations from version 1000 to 'now'.
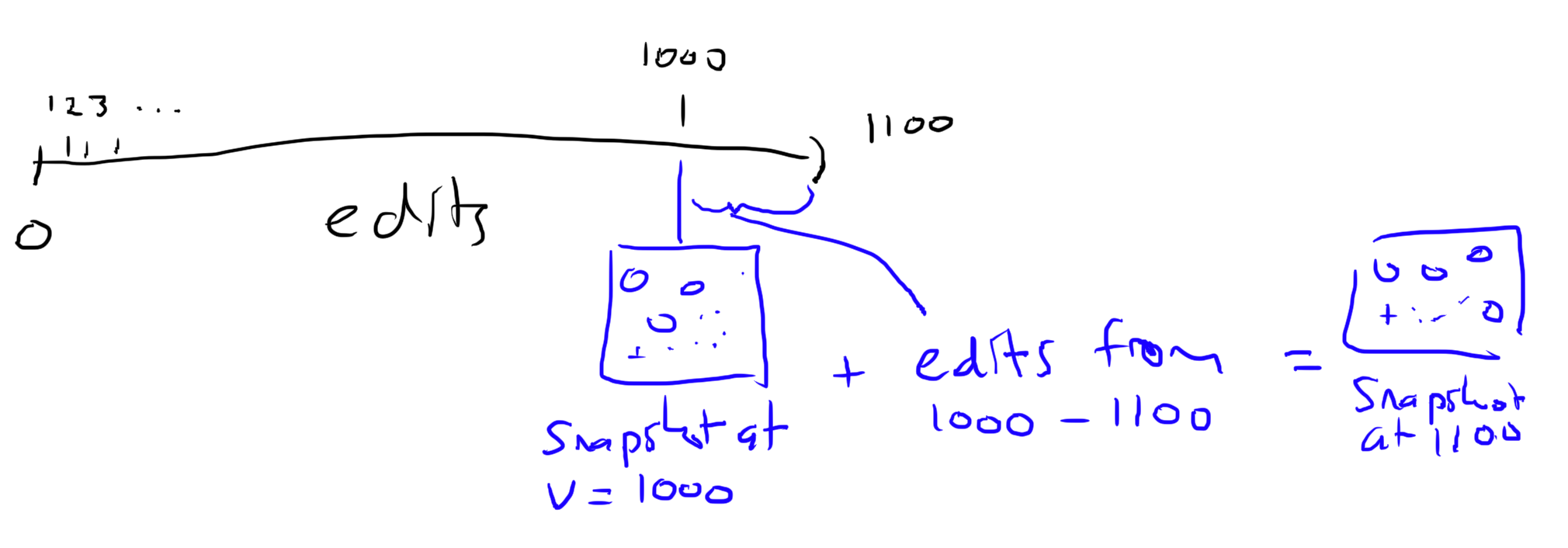
Snapshots
The client needs to load the page quickly without downloading the entire history of operations. To do that I made a REST endpoint which simply returns a PNG of the current page. To make this work the server just stores a copy of the page in a 1000x1000 array in memory. The array gets updated when any edits come through kafka.
But rendering that image out to PNG is slow. I hooked up pngjs to render out the image, and it takes about 300ms of time per render. A single CPU can only render the page 3 times per second. This is way too slow to keep up.
Its probably possible to optimize that. Reddit apparently spent a lot of time bit packing their image in redis, but that sounds like a waste of time to me. I just configured nginx to fetch the image at most once every 10 seconds. All the time in between that nginx will just return a stale image.
But the client can catch up! The cached image has the version number embedded in a header, so when the client connects to the realtime feed it can immediately get a copy of the edits which have happened since the image was generated.
To make server restarts fast, every 1000 edits or so I store a copy on disk of the current snapshot & what version its at. When the server starts up it works just like the client - it grabs that snapshot from disk, updates it with any recent operations from kafka and its good to go.
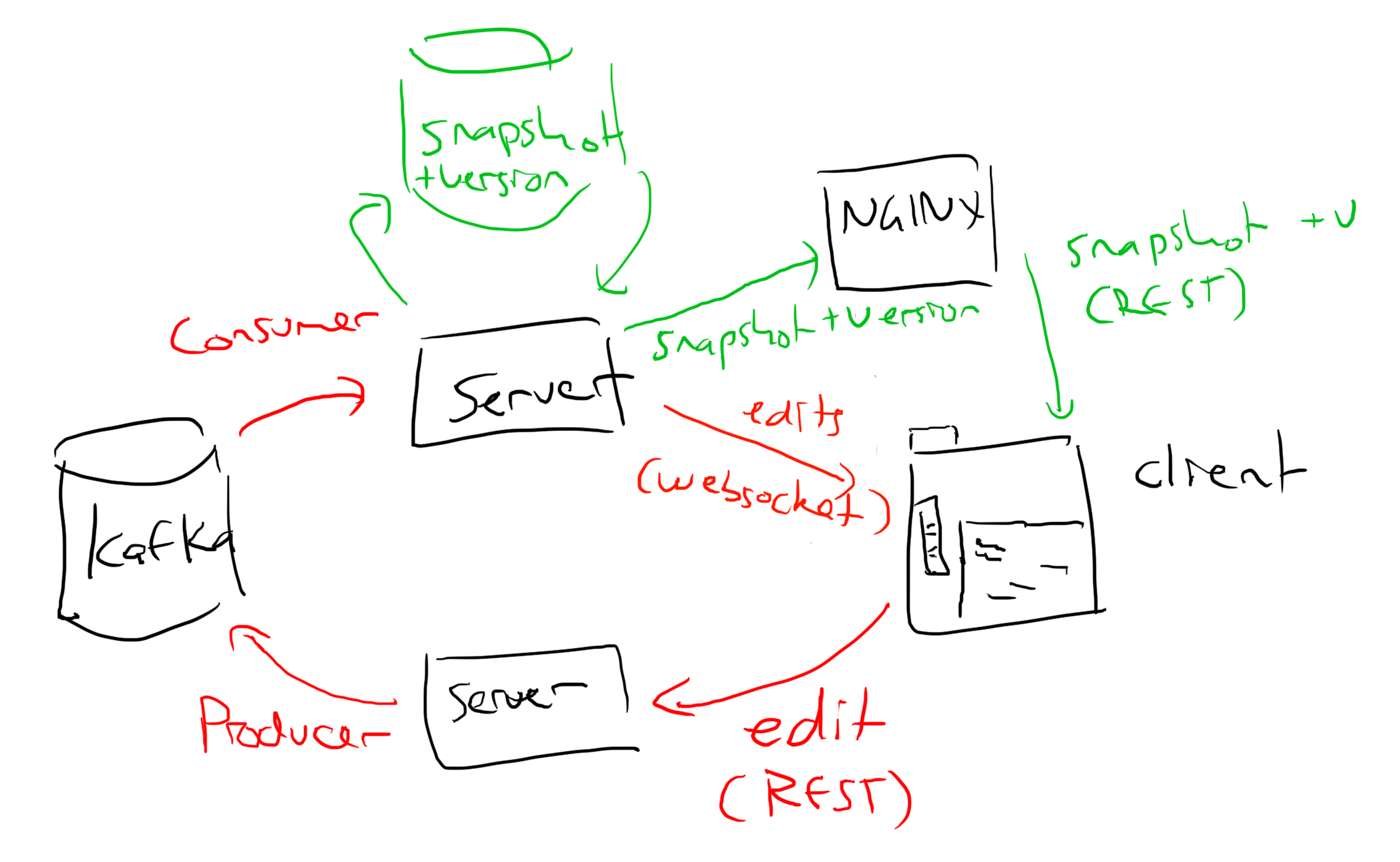
The data flow ends up looking something like this, although the server keeps a recent snapshot in memory and on disk. But again, data only flows one way so each part is easy to reason about in isolation.
Writing the server
At about 2pm on Friday I knew what I was building and I started to work.
I'd never actually used kafka before, and I have a rule with projects like this that any new technology has to be put in first just in case there are unknown unknowns that affect the design. But Kafka was dreamy to work with, so by 4pm I had the kafka events working and the server was rendering images out:
Got simple streaming edits working via kafka. Streaming update API next. #placethrowdown pic.twitter.com/EuEXdZIVYI
— Seph (@josephgentle) April 14, 2017
In the video each edit sets the top left 100 pixels of the image to a random color. I'm triggering the edits via cURL (no browser code yet). The edits are published to kafka. The server gets sent the events from kafka then updates the image. When I refresh the page (actually its just an image URL), the server returns an updated PNG with the new content.
By 6pm I had an endpoint allowing the client to subscribe to a live stream of edits:
SSE working for live updates, with resume & replay. Not sure how to load balance SSE. Client image updating next #placethrowdown pic.twitter.com/lu0e7WHdEb
— Seph (@josephgentle) April 14, 2017
(I used server-sent events instead of websockets at first because they're simpler and more elegant than websockets and they work over HTTP2. But SSE doesn't support binary data, and you need a polyfill for IE so I moved away from them later. More about that later.)
Anyway, with all that done the server was basically complete. I added a few caching headers for the snapshots, put it behind nginx with a strict caching policy and moved to the client.
Making a pixel editor in a browser
Luckily for me, I've already written a few browser games with scrollable and pannable pixel-like editors. So for the editor I blatantly stole a bunch of code from steam dance.
The client works using 2 canvases:
- One invisible canvas for the image itself. This canvas is basically just an image with the whole drawing space in it. This is really simple and efficient because the image has a known, fixed size (1000px x 1000px) so it can fit comfortably in GPU memory.
- The second canvas is the drawable area you see on the page itself. This canvas is in the DOM, and it gets resized when you resize your browser.
Most of the time reddit uses CSS to render their r/place page, and then falls back to using canvases in some browsers. But I don't like needing multiple renderers if I can avoid it.
My draw function was just this:
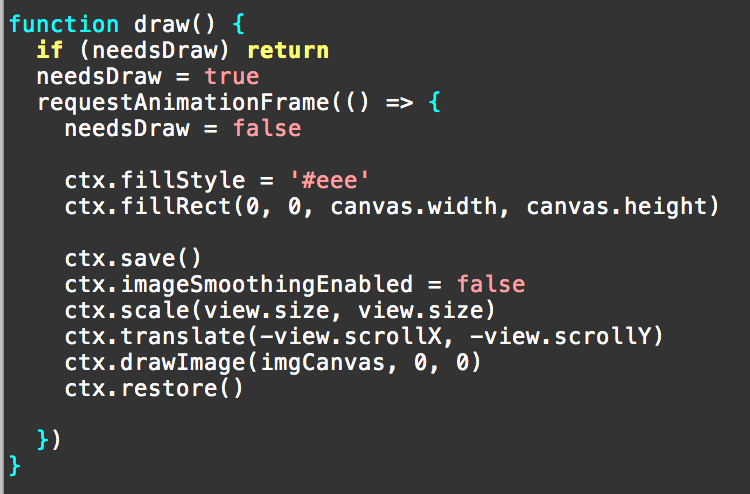
If you haven't seen it before, that wrapper for requestAnimationFrame improves the code in two ways:
- If the tab is in the background, it won't draw at all
- It lets me call
draw()with impunity in my code any time I need something redrawn. The page will only be redrawn once no matter how many calls to draw I make before rendering.
For a game with animations you usually just render at 60fps regardless, but I want sephsplace to be able to sit in the background without using CPU unnecessarily while idle.
For panning and zooming I stole ~150 lines of code from past projects.
Once that was done I added the palette swatches and some UI. By 9:30pm I had a working client:
That asymmetric border radius tho :D. Added pan tool and color selection swatches. Next caching then I want to put it online #placethrowdown pic.twitter.com/1fpEbVRkoa
— Seph (@josephgentle) April 14, 2017
Then I spent hours fighting with java, zookeeper, systemd scripts for kafka, nginx and pm2.
At 2am, 12 hours after starting, I put the site live.
I didn't manage to sleep until 4am though.

Day 2 - Optimization and polish
A good rule of thumb is that if you want to spend any time polishing you'll need twice as much time. So I was very pleased that I had a whole day for tweaks and optimizations.
For this project I was aiming to be able to support reddit's numbers - 100k concurrent users and 333 edits per second. Making numbers go up is really fun, so I always like to measure before optimizing so I can really see the performance metrics shoot up.
Initial testing at 400 edits/second. Its 10x slower than I want but pretty. The real problem will be adding 100k readers tho #placethrowdown pic.twitter.com/nQDUDBVJ73
— Seph (@josephgentle) April 15, 2017
The initial benchmarks were pretty depressing. In the video I have a script running which is sending 400 edits / second into kafka. Every part of this system is slower than I want it to be:
- Chrome is using an entire core of CPU just rendering the animation
- My server is using about 34% of a core simply receiving operations from kafka and sending them out again
- Even kafka is embarrassingly slow here - using 20% CPU to process those 400 ops/second. I expect better from you kafka!
400/second is a really small number for modern computers. The reason we're using so much CPU here is bookkeeping:
- Kafka processes each edit individually
- Kafka sends 1 network packet per edit (I think)
- My server decodes each edit individually using msgpack, into a separate javascript object
- My server then re-encodes each edit to a JSON string to send to the browser
- The client processes each edit individually. For each edit it needs to talk to the GPU to upload that one lonely pixel.
Whew - I'm tired just thinking about it. This is a staggering amount of work for the computer.
To fix this I made 3 changes:
First, we don't need to do this work per-edit! Its much better to batch up all edits into ~10th of a second blocks and process them together. That way we only need to pay for bookkeeping 10 times a second no matter how many messages we have.
Secondly I moved everything to binary messages.
The binary encoding for this is beautiful - each edit fits perfectly into 3 bytes. Look at the math - An edit is a (x, y, color) triple. The x and y coordinates are integers from 0-999 - which is almost perfectly represented as a 10 bit integer (10 bits = 1024 different values). And 16 colors fit exactly in 4 bits.
So we have x (10 bits) + y (10 bits) + color (4 bits) = 24 bits = 3 bytes. Perfect.
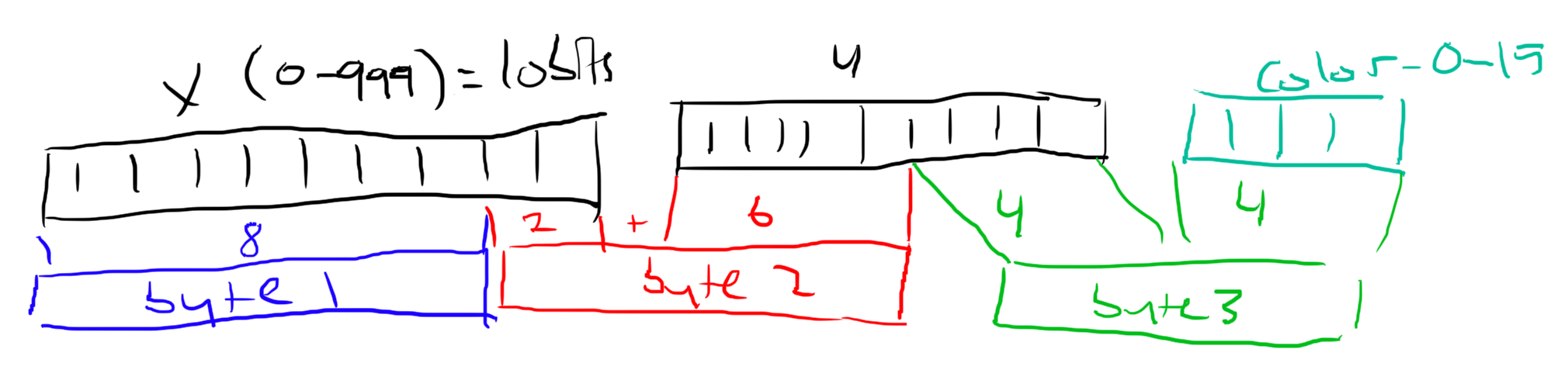
Now I can batch hundreds of edits efficiently in a byte array! This is great because byte arrays are blazing fast. They're much faster because they're easy to optimize for in both hardware and software, they're GC-efficient (compared to JS lists) and they're cheap to access from C code (like, say, the nodejs networking stack).
Also writing bitwise code always makes me feel like I'm in hackers 💕💕
The third change was a move from server-sent events to websockets. I needed to do this because SSE doesn't support binary messages. To send the edits over SSE I'd need to encode them into base64 strings, which would be slow and increase the size of the messages. Websockets support sending binary messages directly, so its easier to just use that.
With that done the same 400 edits per second it looked like this:
Same 400 edits/second, but now coalesced every 200ms in batches on write. Less pretty, but the CPU difference is staggering. #placethrowdown pic.twitter.com/Ncrti7wj92
— Seph (@josephgentle) April 15, 2017
Notice:
- Chrome is down to 10% CPU (from 100%)
- The
nodeprocess (the server) is using 2.5% CPU (down from 35%) - Kafka isn't listed, because it was only using about 1% of my CPU to handle the 5 larger messages every second.
I threw in some more minor optimizations after this video as well - adding more batching, tweaking ws parameters and stuff like that. I love optimizing code - it feels so cleansing.

Are we fast enough yet?
Where are the actual performance bottlenecks here? What needs to be fast?
It turns out the big scaling challenge here is actually getting data from kafka to the clients.
Why? Well, because even in the naive version of my code I could handle the required 333 writes per second easily. Thats a tiny number. But remember we need to support 100k active clients. So if the server gets 333 edits per second, it needs to send 33.3 million edits per second.
On paper, 333 writes * 3 bytes = 1k of data. Sending 1k of data per second to 100k clients is 100MB/s of traffic. Which is large but manageable. A well optimized C program should be able to send 100MB of network traffic per second no sweat.
What I really want is something like nginx, but designed for event logs. It should be written in C (node won't be fast enough). The closest I found was nginx-push-stream - which looks perfect. Its designed for exactly this use case. But I don't like it because it doesn't guarantee message order or delivery. Remember, we need a consistent message order so everyone sees the same result when two people edit the same pixel at the same time.
Effectively, nginx-push-stream is UDP and I want TCP. It'd definitely be good enough for this project, but I don't want to have to write the code to replay and reorder messages. And to use it I'd need a worker process which simply tails the kafka log and forwards it into nginx. And we'd need need special catchup-on-reconnect logic, because the stream it sends out wouldn't support subscribing from a specified version number.
Another approach would be to send the events out using long polling. That sounds wild, but if we make a URL for each block of edits, the clients could just request the next block of edits directly from nginx. Nginx can be configured to hold all 100k requests from clients and just send 1 request to the backend for the data. The server then holds the request until the data is available (ie, 1 second has passed). If we get nginx to cache the edits, it'll support catchup just fine.
Its just... sad doing it that way. Long polling is so... 2005. And its a pretty weird way to use of nginx.
In this case I'm lucky to say I didn't need to do any of that. It turns out my binary message handling + ws is fast enough anyway:
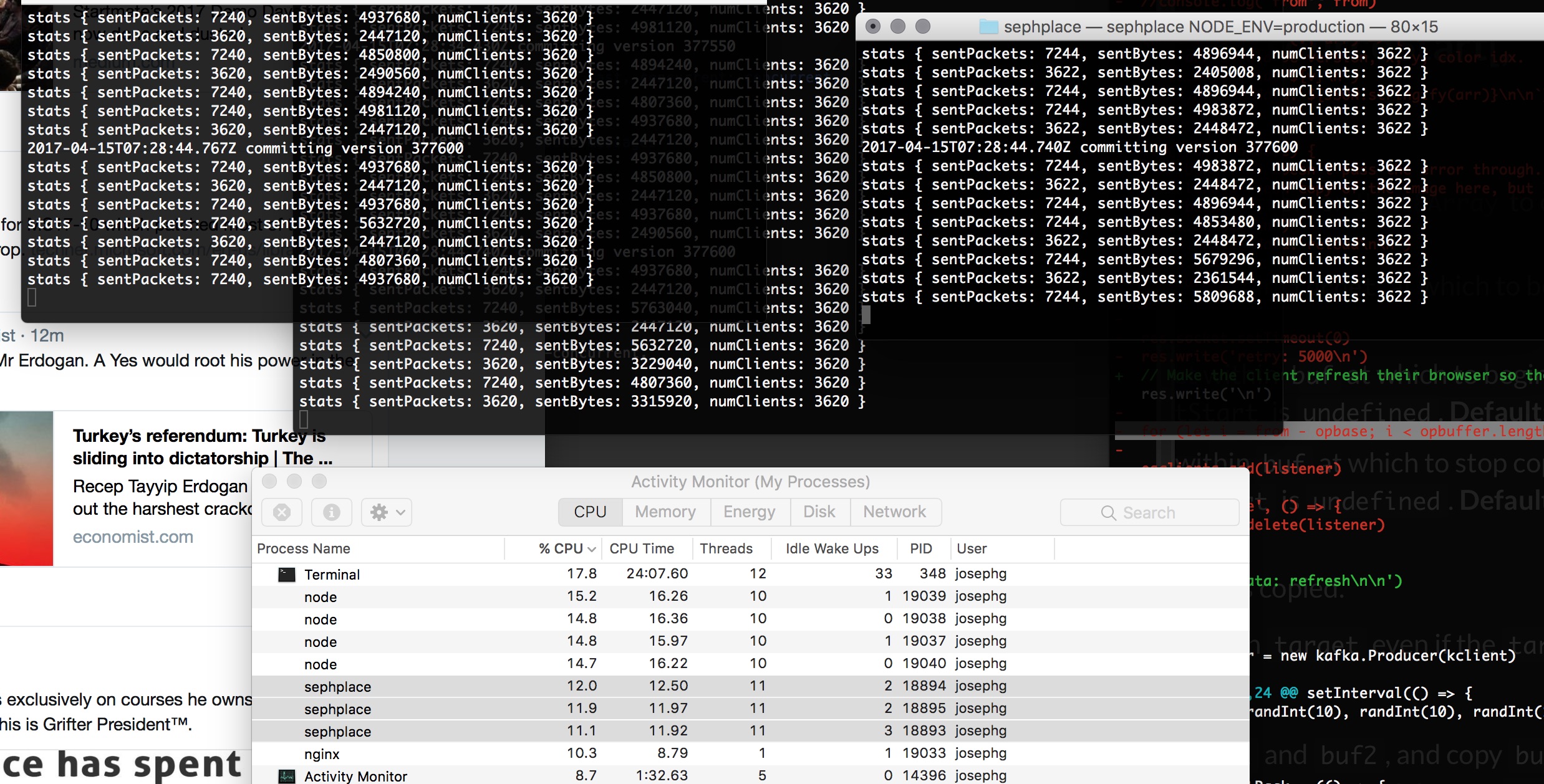
My laptop manages 10k clients using only about 34% of one CPU core. So 100k clients should take about 4 modern CPU cores. This is several times faster than I expected it would be. I'm grateful for the performance optimizations that have gone into the ws websocket library, nodejs and v8 over the last few years. Horizontal scaling like this will put extra load on kafka, but kafka can handle a few more orders of magnitude of load before we need to worry about it.
(The node processes you see in the screenshot are the websocket testing library thor. I had to modify it a little to work for me though.)

So that was that. At 5:30pm on day 2 I declared the challenge complete.
If I was feeling virtuous or better rested I would have rented a few AWS machines and set up a full cluster. But the thought of spending hours setting up zookeeper again was enough to convince me to declare victory and play some computer games instead.
It'll be fine. We can fix it live if we need to, right?

Final thoughts
That was a wild ride. I haven't gotten much sleep, and I spent altogether too much time deleting nazi symbols and penises. And fighting botnets used to draw giant pictures of Angela Merkel.
I think if I make something like this again I'd like to live stream the whole thing. One of the most enjoyable parts of the process was going online and seeing what people have drawn. This sort of project is a real community thing, and I'd like to involve the community more in the future.
As for the site - I don't know what to do with it. I'll leave it up, but I'm worried people will start drawing child porn or something if I don't keep an eye on it.
While working on this I feel like the most interesting design question is the policy on rate limiting:
- Bots are cool, but way more powerful than humans
- If you limit edits to once per 5 minutes, will I have enough community to keep it going?
Maybe I could make a version where every user has an energy bar. Then different areas of the space are either more or less volatile - so you can draw on the volatile sections for free, but its easy for others to draw over the top. If you want your art to stay for a long time you can draw in the slow regions - it'll just take ages to draw in the first place. Or maybe the space should start small with just one small tile, and the community can slowly add tiles. Each tile can only be edited for 24 hours then it gets locked down forever, forming a slowly growing mosaic. I'm sure there's lots of cool variants.
Thankyou reddit for making r/place and inspiring me. And thanks to everyone who's drawn awesome stuff on the page, and followed along on twitter. Its been fun!
Ugh, I feel weak.. did I forget to eat again? ... Oops.
