Databases have failed the web
Part 1 - a history lesson
The year is 1980. Last year RSI released Oracle V2, the world's first commercial SQL database for the PDP-11:

At an unnamed bank you have rooms full of computers like the PDP-11, with specialized computer operators to keep them running. 'Dumb terminals' at people's desks allow ordinary office workers to interact with the computer system.

How do you use your new state of the art SQL database? First you had to hire expensive DBAs (database administrators). After reading hundreds of pages of manuals these technicians would issue SQL commands directly. But the database is so fantastically useful that everyone needs to interact with it, down to lowly cashiers. Over the next few years you'll commission software to make interacting with the database easier; automating common tasks and making sure clerks can't accidentally wipe important records with a few misplaced keystrokes.
But in 1980 the writing was on the wall for the PDP-11. The microcomputer craze is in full force, arguably the first of three major reinventions of the computing ecosystem over the next few decades. But we don't know that yet. All we know is that the Apple II came out last year with Visicalc. Next year IBM will release their first Personal Computer. Pretty soon Microsoft will make its play too. "A computer on every desk and in every home, running Microsoft software."
But that hasn't happened yet. But we can see now what survived from that period (or earlier):
- The idea of a special computer called a 'server'.
- The C programming language (invented in 1972)
- Structured Query Language, (SQL) used to talk to the database (invented in 1974)
- The VT-100 terminal protocol. (All modern *nix and mac terminals pretend to be an old VT-100. Crazy huh?)
Almost everything else has been reinvented over and over again in the decades since.
Lets jump forward to 1995. What does the same office look like? Well that VT100 terminal won't cut it anymore. Office workers have whole computers on their desks all to themselves. Microcomputers with more capacity than rooms full of mainframes had just a decade ago. Windows NT 3.5 will be released this year; a landmark achievement for microsoft. An operating system with a full TCP/IP networking stack. But don't worry - SQL is still there holding all our customer records. It runs in data centres on big servers. Employees access the SQL database through application software on their workstations. (Oh yeah, we call them workstations now.)
From an architectural point, what changed? Well before the SQL server was a multi-user process (all programs interacting with the database ran on the mainframe itself). Now the SQL server runs alone, though it exposes itself to applications through TCP/IP ports. Application software on workstations throughout the office will connect to the SQL server, authenticate and make queries. The data will be displayed to the office worker in some native Windows application. They can modify fields, insert rows and generate graphs. Its all very fancy.
Access control is quite coarse, but thats ok because access to the database is restricted to employees. They'll need access to the corporate network and a login to the database to do anything. Past those barriers, its probably fine. So long as nobody runs any particularly slow queries or types in the wrong SQL commands directly into the SQL console everything will be fine. (Systems at this time were massively vulnerable to SQL injection attacks but again, your employees just wouldn't do something like that so nobody was too worried).
When the application wanted to make a change to the data, it was easy. The application would validate the new data then insert it into the database directly (using INSERT INTO ... statements). If your DBAs were fancy I'm sure some people used PL/SQL and other languages embedded in the database itself, but they were always a pain to work with.
But other than having to manually craft SQL commands out of strings, life was looking pretty great.
Part 2
But this is where the story gets a lot sadder. Another revolution happened, and nobody is going to tell the old database servers. Actually if you took a DBA from the 80's and showed them a modern laptop running PostgreSQL in a terminal emulator (which emulates the VT-100, remember), they'd be right at home. So at home it'd be embarrassing. Our databases have gotten faster, and they scale better. Buttttt..... we forgot to tell the database that the world changed.
Of course, I'm talking about the web. Or the cloud, if thats how you think about it.
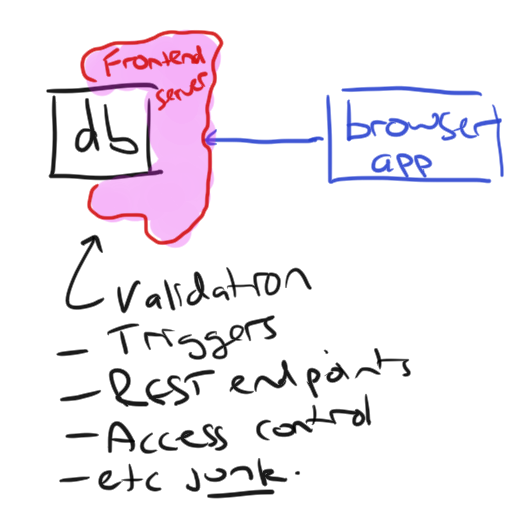
Its like the database people said "Your website is basically a desktop app. The database is fine..." and they got to work tweaking it to be faster and more clever. To implement a frozen spec better. And web developers, descendants of the old frontend application developers said "Whatever, we can work around it in software anyway". And then they got to work writing database middleware in PHP.
And it was good. cough Ahahaha just kidding... it was terrible. To work around the lack of features in modern databases, we had to invent a third kind of thing. Not a database, not an application - but an application server. What does it do? Well, it uh.. takes the data from the browser, and sends it to the database. And takes the data from the database and sends it to the browser.
Why is this needed? Well 3 reasons:
- Access control on modern databases is too coarse. You want to whitelist which queries a user is allowed to make and you want fine-grained permissions around updates
- Databases only talk custom binary TCP protocols, not HTTP. Not REST. Not websockets. So you need something to translate between how the server works and how the browser works.
- You want to write complex logic for user actions, with custom on-save triggers and data validation logic.
Because these features are tied to the application and data model, they're almost always bespoke systems. I have a degree in computer science, but I've wasted oh so many hours of my life writing variants of the same plumbing code over and over again. Take the data from here, validate it, make a database update request then respond to the browser based on what the database says...
And its hard to write this code correctly. You need to do correct data validation. Check for XSS and protect against SQL injection attacks. And DOS attacks from maliciously crafted queries. Set correct caching headers. Don't overfetch or underfetch data. Implement server side rendering and cache some more.
Entire language ecosystems have grown around solving this problem. PHP. Tomcat. Django. Rails. Node. ORMs became a thing - ActiveRecord for Rails, Mongoose for Node. XML, SOAP, JSON, GraphQL. And all the rest.
All because we're programming against a frozen database spec. Our frontend servers act as a weird form of tumour growing around our databases, injecting themselves as a suture over a broken API.
And its 2016 already. I want a bonus 4th missing feature that will never be plumbed manually through every damn REST endpoint. I want realtime updates. Modern databases are eventually-consistent, but only to the boundary of their replica set for some reason??? The industry standard is to simply not tell the user when the data they're looking at is stale.
Why don't modern databases simply provide these features? I don't know. I can guess, but I wont be charitable. Because its hard. Because modern web apps are too new, and server rendered apps look too much like the old desktop apps to give anyone pause. Because database developers don't write frontend code. Because we've had database triggers for ages (though they're still terrible to use, and they don't solve the whole problem).
And yes, because we are fixing it with tools like Firebase and Horizon.
But they aren't good enough yet. Along with composability operators I think its time to write some code.